Biology 101 guide for non-scientific life science employees
Working in such a broad and complex sector as the life science industry, it isn’t possible to be an expert in every field our companies and colleagues work in.
Introduction
I hope to break down some of the basics of scientific jargon used every day in the life sciences sector because when we don’t understand the complexity and beauty of the meaning of these words, we don’t appreciate the incredible effort scientists put into laboratories every day to push humanities’ understanding of our bodies and preventing diseases.
Starting simply, we all know we are made out of cells. We all start with one cell (the egg) and by the division of the cell, we become 37.2 trillion cells (average) as an adult (1).
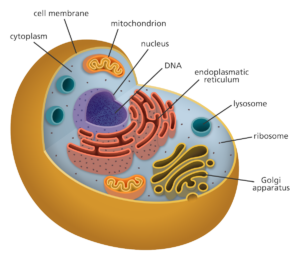 Figure 1. A cell, by its irregular and round shape we know this to be an animal cell. (2)
Figure 1. A cell, by its irregular and round shape we know this to be an animal cell. (2)
Keeping the cytoplasm together is an oil layer we call a membrane. Just like we have organs in our bodies that function differently to each other together, vital to keeping us alive, so too does the cell, with organelles scattered in the cytoplasm. The mitochondria provide energy and the nucleus holds the cell’s genetic material, to name but a couple.
The deoxyribonucleic acid, DNA for short, is the recipe for life in all the complex organisms we know. A set of instructions so long and complex that in writing it would require three thousand books, each 1,000 pages long. Since you have a copy of the same DNA in every cell of your body (and you have trillions of cells), you can imagine DNA is ultra-compact and richly dense in information (3).
Now we are all thinking of the legendary double helix. This shape gets tightly folded into structures called chromosomes. Humans have 23 pairs of chromosomes, one coming from the mother and one from the father. Bearing in mind that the number of chromosomes or having longer DNA does not correlate to the complexity of the organism. For example, butterflies have 96 pairs; dogs have 39 (4,5).
Complexity of DNA
We ‘ve established that each chromosome is made up of tightly coiled DNA, containing the genes or the “recipes” for proteins. DNA is like the precious cookbook your grandmother left when she passed away and that has the best recipes you ever tasted. The organelles (or the cooks in this analogy), which are going to cook the recipes, are called ribosomes and are outside the nucleus, inside the cell. DNA is kept in the nucleus and it never leaves. So the cell makes copies of a required gene, throws it out to the cytoplasm so the ribosome can translate it into a protein. Similar to when your friend asks for instructions, you copy the recipe and give that away rather than giving the precious book away. Now, the short copies of DNA are called ribonucleic acid, RNA for short.
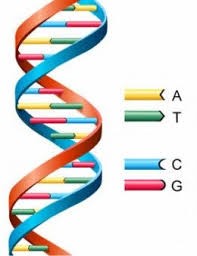
Like codes in a computer made out of 0s and 1s, our genetic code (or the recipe) is made out of 4 molecules called nucleotides which are adenine, guanine, cytosine and thymine or A, G, C and T respectively.
To be able to understand how a sequence of nucleotides can make a protein such as insulin, and ultimately very complex organisms, first, we need to understand our essential structural component, the proteins.
Figure 2. Double helix showing nucleotides (6)
Amino acids are building blocks of proteins which have complex structures. The amino acids bond together through peptide bonds forming polypeptide chains. One or more polypeptide chains twisted into a 3-D shape, folds, loops, and curves to form a protein.
Going back to ribosomes, they read the nucleotide sequence in triplets and then match the nucleotides to their respective amino acid. Every three nucleotides (called a codon) code for an amino acid, for example, AAG would code for the amino acid phenylalanine or CGA would code for amino acid arginine. As amino acids line up, they bond together through peptide bonds. This forms a chain of amino acids (polypeptides), these chains inside the cell bind together with other polypeptides and form complex proteins such as insulin. In most species insulin is made out of 2 polypeptides, which are of 21 and 30 amino acids each (7).
We’ve established what DNA does, but how do our cells replicate the giant molecule trillions of times?
First, the two strands of the DNA are “unzipped”, for want of a better word, since each nucleotide only pairs with a particular complementary nucleotide — G with C and T with A — each strand complements the other (8). Each nucleotide has a chemical affinity for its complementary nucleotide, large numbers of which, are floating around waiting to bind to DNA. When the strand separates, free nucleotides that are floating around bind to the now unbounded strands.
Mistakes do happen during this process, especially if you are a frequenter of lying on a sunbath absorbing all the ultraviolet light weakening the bonds between the nucleotides. These permanent changes in the genetic material called mutations. They range in size; they can affect anywhere from a single DNA base pair to a large segment of a chromosome that includes multiple genes. Some mutations occur in areas that code for very important proteins while some have little effect. Some mutations cause the cells to grow and reproduce uncontrollably. This is what causes the major epidemic of the twenty-first century, cancer (9).
When I read the news about scientists discovering the gene for breast cancer or when hear about gene therapy treating people, I think about what that means and how much work that requires. And let us not forget, no matter what, your cells are always working hard, so remember to respect them with proper care!
REFERENCES
(1) Bianconi, E., Piovesan, A., Facchin, F., Beraudi, A., Casadei, R., Frabetti, F., Vitale, L., Pelleri, M., Tassani, S., Piva, F., Perez-Amodio, S., Strippoli, P. and Canaider, S. (2013). An estimation of the number of cells in the human body. Annals of Human Biology, 40(6), pp.463-471.
(2) What is a cell, 2017 Online. [Accessed 28 May 2019]. Available from: https://www.yourgenome.org/facts/what-is-a-cell.
(3) Brown TA. Genomes. 2nd edition. Oxford: Wiley-Liss; 2002. Chapter 1, The Human Genome. Available from: https://www.ncbi.nlm.nih.gov/books/NBK21134.
(4) Vershinina, A. and Lukhtanov, V. (2017). Evolutionary mechanisms of runaway chromosome number change in Agrodiaetus butterflies. Scientific Reports, 7(1).
(5) Lindblad-Toh, K., Wade, C., Mikkelsen, T., Karlsson, E., Jaffe, D., Kamal, M., Clamp, M., Chang, J., Kulbokas, E., Zody, M., Mauceli, E., Xie, X., Breen, M., Wayne, R., Ostrander, E., Ponting, C., Galibert, F., Smith, D., deJong, P., Kirkness, E., Alvarez, P., Biagi, T., Brockman, W., Butler, J., Chin, C., Cook, A., Cuff, J., Daly, M., DeCaprio, D., Gnerre, S., Grabherr, M., Kellis, M., Kleber, M., Bardeleben, C., Goodstadt, L., Heger, A., Hitte, C., Kim, L., Koepfli, K., Parker, H., Pollinger, J., Searle, S., Sutter, N., Thomas, R., Webber, C. and Lander, E. (2005). Genome sequence, comparative analysis and haplotype structure of the domestic dog. Nature, 438(7069), pp.803-819.
(6) How to Explain DNA to Kids, 2016 Online. [Accessed 28 May 2019]. Available from: https://owlcation.com/academia/explaining-dna-to-a-six-year-old.
(7) Selivanova, O., Grishin, S., Glyakina, A., Sadgyan, A., Ushakova, N. and Galzitskaya, O. (2018). Analysis of Insulin Analogs and the Strategy of Their Further Development. Biochemistry (Moscow), 83(S1), pp.S146-S162.
(8) Brenner, S. and Miller, J. (2014). Brenner’s Encyclopedia of Genetics. Saint Louis: Elsevier Science.
(9) Kaidar-Person, O., Bar-Sela, G. and Person, B. (2011). The Two Major Epidemics of the Twenty-First Century: Obesity and Cancer. Obesity Surgery, 21(11), pp.1792-1797.




